这篇文章已超过一年。较旧的文章可能包含过时内容。请检查页面中的信息自发布以来是否已失效。
使用 OpenTelemetry 提升 Kubernetes 容器运行时可观测性
谈论云原生空间的可观测性时,大家很可能会在某个时候提到 OpenTelemetry (OTEL)。这很棒,因为社区需要依赖标准来将所有集群组件引向同一个方向。OpenTelemetry 使我们能够将日志、指标、追踪和其他上下文信息(称为行李)组合到一个资源中。集群管理员或软件工程师可以使用此资源来获取集群在特定时间段内的视图。但 Kubernetes 本身如何利用这一技术栈呢?
Kubernetes 由多个组件组成,其中一些是独立的,另一些则堆叠在一起。从容器运行时角度看架构,从上到下有:
- kube-apiserver:验证 API 对象的配置和数据
- kubelet:运行在每个节点上的代理
- CRI runtime:容器运行时接口 (CRI) 兼容的容器运行时,如 CRI-O 或 containerd
- OCI runtime:更低层的 Open Container Initiative (OCI) 运行时,如 runc 或 crun
- Linux kernel 或 Microsoft Windows:底层操作系统
这意味着如果我们遇到在 Kubernetes 中运行容器的问题,我们会从这些组件之一开始查找。找到问题的根本原因是我们应对当今集群设置日益增加的架构复杂性时面临的最耗时的任务之一。即使我们知道哪个组件似乎导致了问题,我们仍然必须考虑其他组件,以便在脑海中维护一个正在发生的事件的时间线。我们如何做到这一点?嗯,大多数人可能会坚持抓取日志,过滤它们,并将它们跨组件边界组合在一起。我们也有指标,对吧?没错,但将指标值与纯日志关联起来会使追踪正在发生的事情变得更加困难。有些指标也并非用于调试目的。它们是根据集群终端用户的视角定义的,用于关联可用的告警,而不是供开发者调试集群设置。
OpenTelemetry 应运而生:该项目旨在将 追踪、指标 和 日志 等信号结合起来,以保持对集群状态的正确视图。
OpenTelemetry 追踪在 Kubernetes 中的现状如何?从 API Server 的角度来看,自 Kubernetes v1.22 起我们有了追踪的 Alpha 支持,它将在未来的某个版本中晋升为 Beta。遗憾的是,它错过了 v1.26 Kubernetes 发布。可以在 Kubernetes Enhancement Proposal (KEP)《API Server Tracing》 中找到设计提案,它提供了更多信息。
Kubelet 的追踪部分在 另一个 KEP 中跟踪,该 KEP 已在 Kubernetes v1.25 中以 Alpha 状态实现。截至撰写本文时,尚未计划晋升为 Beta,但在 v1.27 发布周期中可能会有更多进展。除了这两个 KEP,还有其他一些努力正在进行中,例如 klog 正在考虑支持 OTEL,这将通过将日志消息链接到现有追踪来提升可观测性。在 SIG Instrumentation 和 SIG Node 内部,我们还在讨论 如何将 kubelet 追踪关联起来,因为目前它们主要关注 kubelet 和 CRI 容器运行时之间的 gRPC 调用。
CRI-O 自 v1.23.0 起支持 OpenTelemetry 追踪,并持续进行改进,例如 将日志附加到追踪 或扩展 span 到应用程序的逻辑部分。这有助于追踪的用户获得与解析日志相同的信息,但具有更强的范围界定和过滤到其他 OTEL 信号的能力。CRI-O 维护者还在开发一个用于替代 conmon 的容器监控工具,名为 conmon-rs,它是完全用 Rust 编写的。使用 Rust 实现的一个好处是能够添加 OpenTelemetry 支持等功能,因为相关的 crate(库)已经存在。这使得与 CRI-O 的紧密集成成为可能,并让使用者能够看到其容器最底层的追踪数据。
containerd 自 v1.6.0 起添加了追踪支持,该支持 可通过插件使用。更底层的 OCI 运行时,如 runc 或 crun,完全不支持 OTEL,并且似乎也没有相关的计划。我们始终需要考虑收集追踪以及将其导出到数据接收器时会产生的性能开销。但我仍然认为值得评估一下在 OCI 运行时中扩展遥测数据收集会是什么样子。让我们看看 Rust OCI 运行时 youki 未来是否会考虑类似的事情。
我将向你展示如何尝试一下。我的演示将使用一个单节点本地栈,包含 runc、conmon-rs、CRI-O 和 kubelet。要启用 kubelet 中的追踪,我需要应用以下 KubeletConfiguration:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
featureGates:
KubeletTracing: true
tracing:
samplingRatePerMillion: 1000000
samplingRatePerMillion 等于一百万,在内部将转换为采样所有内容。类似的配置必须应用于 CRI-O;我可以启动带有 --enable-tracing 和 --tracing-sampling-rate-per-million 1000000 标志的 crio 二进制文件,或者使用如下的 drop-in 配置:
cat /etc/crio/crio.conf.d/99-tracing.conf
[crio.tracing]
enable_tracing = true
tracing_sampling_rate_per_million = 1000000
要配置 CRI-O 使用 conmon-rs,你需要至少 CRI-O v1.25.x 的最新版本和 conmon-rs v0.4.0。然后可以使用如下的配置 drop-in 使 CRI-O 使用 conmon-rs:
cat /etc/crio/crio.conf.d/99-runtimes.conf
[crio.runtime]
default_runtime = "runc"
[crio.runtime.runtimes.runc]
runtime_type = "pod"
monitor_path = "/path/to/conmonrs" # or will be looked up in $PATH
就是这样,默认配置将指向一个 OpenTelemetry collector gRPC 端点 localhost:4317,该端点也必须运行。有多种方法可以运行 OTLP,如 文档中所述,但也可以通过 kubectl proxy 连接到 Kubernetes 中运行的现有实例。
如果一切设置完毕,collector 应该会记录有传入的追踪:
ScopeSpans #0
ScopeSpans SchemaURL:
InstrumentationScope go.opentelemetry.io/otel/sdk/tracer
Span #0
Trace ID : 71896e69f7d337730dfedb6356e74f01
Parent ID : a2a7714534c017e6
ID : 1d27dbaf38b9da8b
Name : github.com/cri-o/cri-o/server.(*Server).filterSandboxList
Kind : SPAN_KIND_INTERNAL
Start time : 2022-11-15 09:50:20.060325562 +0000 UTC
End time : 2022-11-15 09:50:20.060326291 +0000 UTC
Status code : STATUS_CODE_UNSET
Status message :
Span #1
Trace ID : 71896e69f7d337730dfedb6356e74f01
Parent ID : a837a005d4389579
ID : a2a7714534c017e6
Name : github.com/cri-o/cri-o/server.(*Server).ListPodSandbox
Kind : SPAN_KIND_INTERNAL
Start time : 2022-11-15 09:50:20.060321973 +0000 UTC
End time : 2022-11-15 09:50:20.060330602 +0000 UTC
Status code : STATUS_CODE_UNSET
Status message :
Span #2
Trace ID : fae6742709d51a9b6606b6cb9f381b96
Parent ID : 3755d12b32610516
ID : 0492afd26519b4b0
Name : github.com/cri-o/cri-o/server.(*Server).filterContainerList
Kind : SPAN_KIND_INTERNAL
Start time : 2022-11-15 09:50:20.0607746 +0000 UTC
End time : 2022-11-15 09:50:20.060795505 +0000 UTC
Status code : STATUS_CODE_UNSET
Status message :
Events:
SpanEvent #0
-> Name: log
-> Timestamp: 2022-11-15 09:50:20.060778668 +0000 UTC
-> DroppedAttributesCount: 0
-> Attributes::
-> id: Str(adf791e5-2eb8-4425-b092-f217923fef93)
-> log.message: Str(No filters were applied, returning full container list)
-> log.severity: Str(DEBUG)
-> name: Str(/runtime.v1.RuntimeService/ListContainers)
我可以看到 span 有一个 trace ID,并且通常附加了一个父 span。事件(例如日志)也是输出的一部分。在上面的例子中,kubelet 通过 Pod Lifecycle Event Generator (PLEG) 定期触发到 CRI-O 的 ListPodSandbox RPC。可以通过 Jaeger 等工具显示这些追踪。如果在本地运行追踪栈,Jaeger 实例默认应暴露在 https://:16686。
ListPodSandbox 请求在 Jaeger UI 中直接可见:
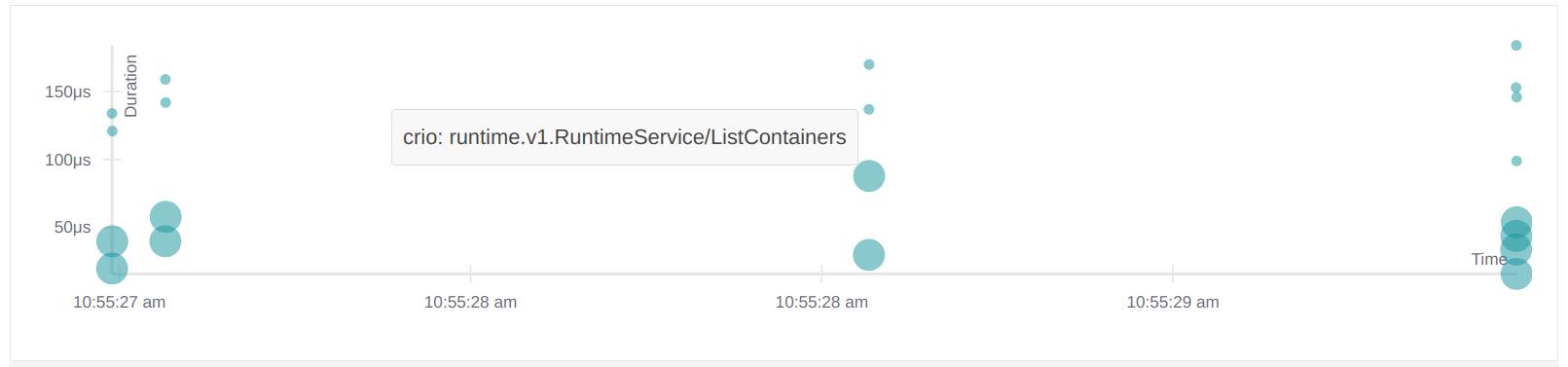
这还不是太令人兴奋,所以我要直接通过 kubectl 运行一个工作负载:
kubectl run -it --rm --restart=Never --image=alpine alpine -- echo hi
hi
pod "alpine" deleted
现在查看 Jaeger,我们可以看到针对 conmonrs、crio 以及 kubelet 的 RunPodSandbox 和 CreateContainer CRI RPC 请求都有追踪:
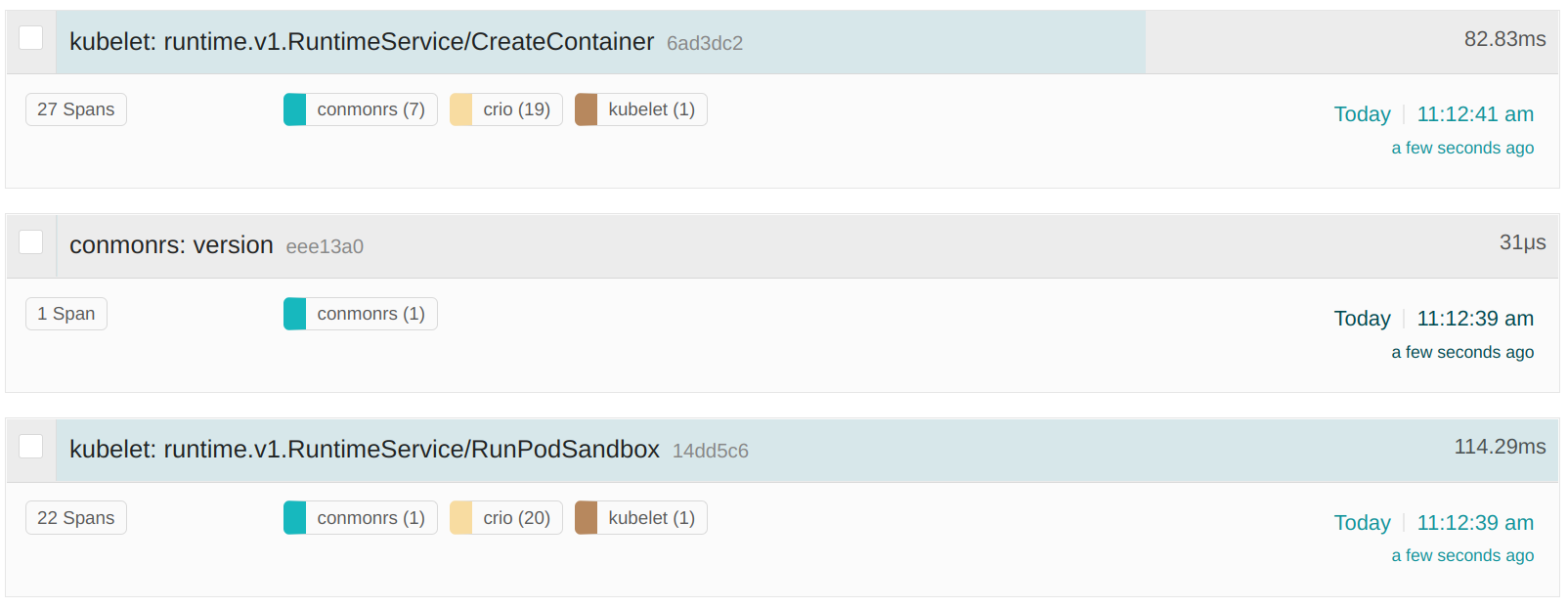
kubelet 和 CRI-O 的 span 相互连接,使得调查更加容易。如果我们现在仔细查看这些 span,可以看到 CRI-O 的日志正确地与相应的功能相关联。例如,我们可以从追踪中提取容器用户,如下所示:
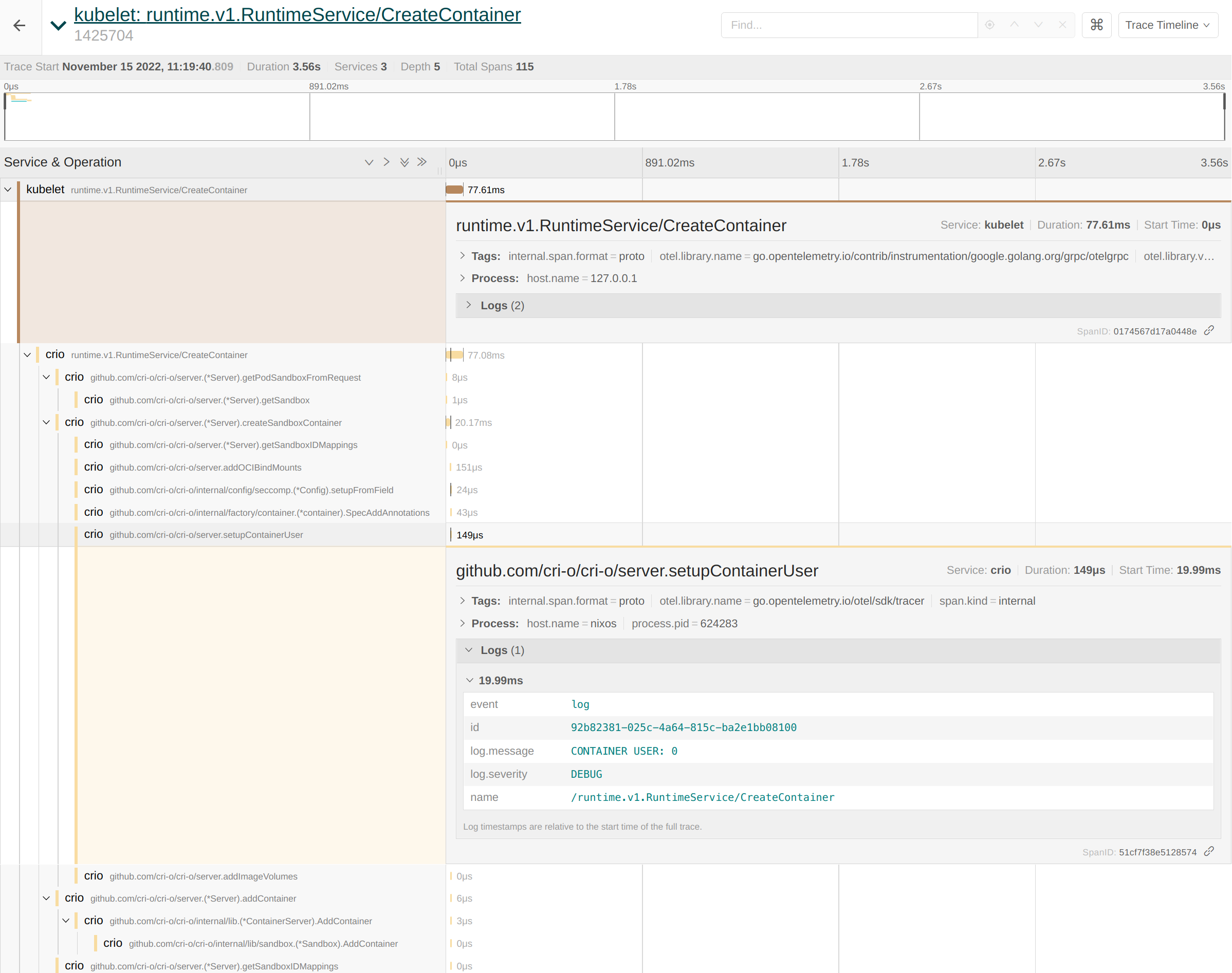
conmon-rs 的底层 span 也是此追踪的一部分。例如,conmon-rs 维护一个内部的 read_loop 用于处理容器和终端用户之间的 IO。读取和写入字节的日志是该 span 的一部分。同样适用于 wait_for_exit_code span,它告诉我们容器以退出码 0 成功退出:
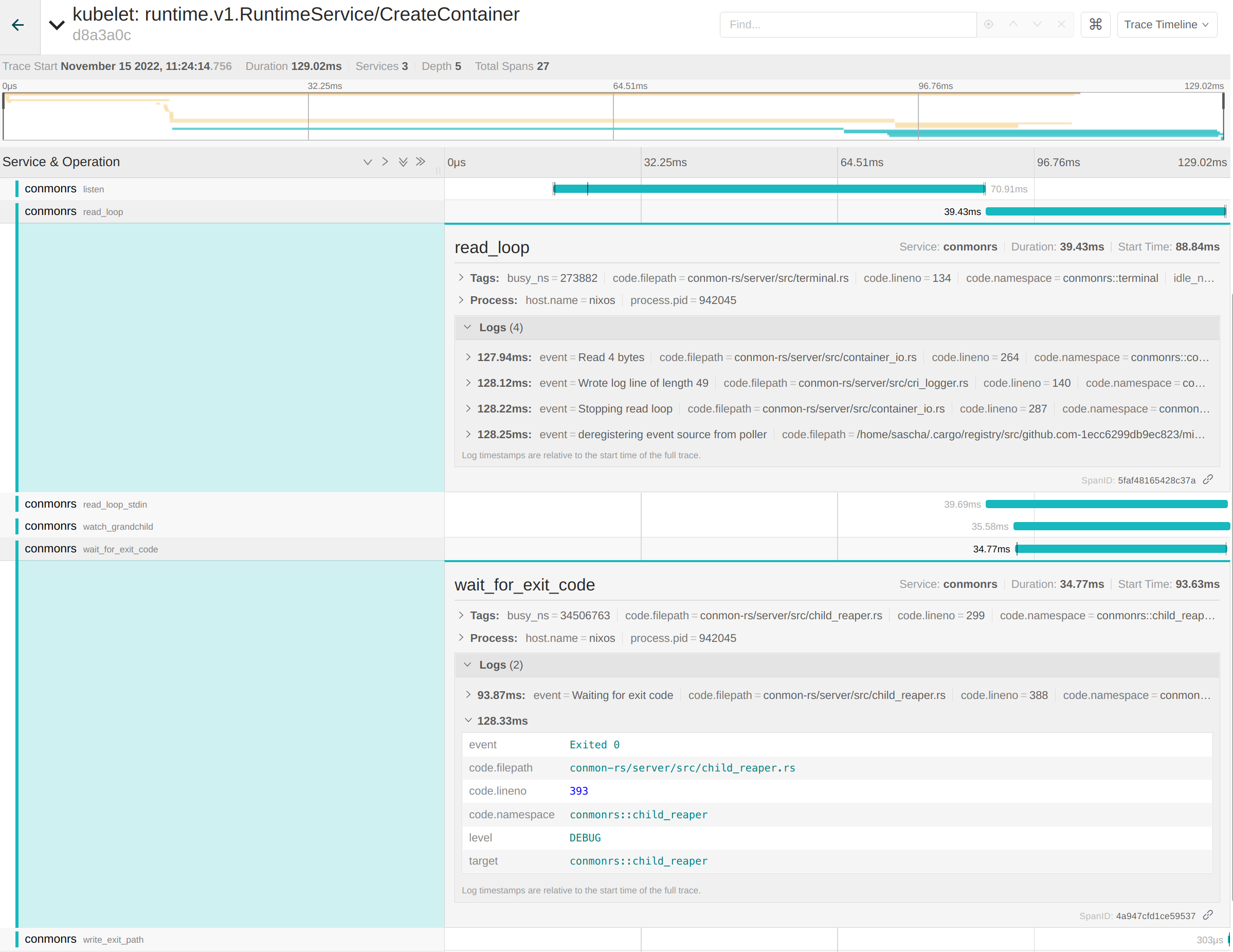
将所有这些信息与 Jaeger 的过滤能力并列,使得整个技术栈成为调试容器问题的绝佳解决方案!提到“整个技术栈”也展示了这种整体方法的最大缺点:与解析日志相比,它在集群设置之上增加了明显的开销。用户必须维护一个 sink,如 Elasticsearch 来持久化数据,暴露 Jaeger UI,并可能需要考虑性能下降。无论如何,这仍然是提高 Kubernetes 可观测性的最佳方法之一。
感谢阅读这篇博文,我非常有信心,展望未来,OpenTelemetry 在 Kubernetes 中的支持将会使故障排除变得更简单。